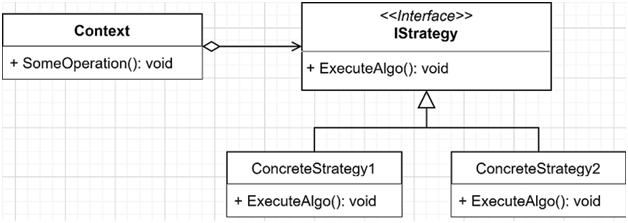
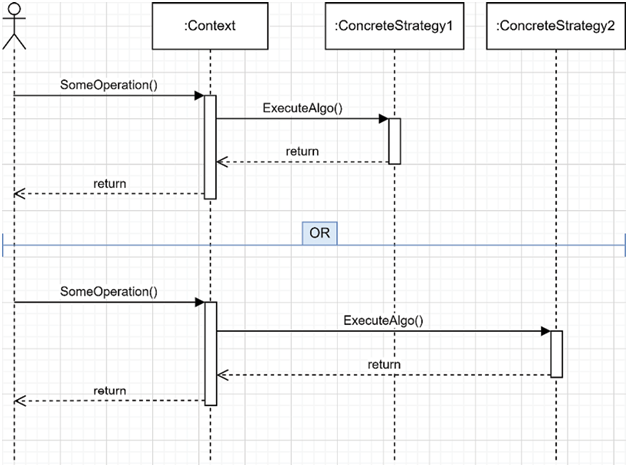
Context: We want to sort a collection differently, eventually even using different sort algorithms (out of the scope of the example but possible). Initially, we want to support sorting the elements of any collection in ascending or descending order.To achieve this, we need to implement the following building blocks:
- The Context is the SortableCollection class.
- The IStrategy is the ISortStrategy interface.
- The concrete strategies are:
- SortAscendingStrategy
- SortDescendingStrategy
The consumer is a small REST API that allows the user to change the strategy, sort the collection, and display the items. Let’s start with the ISortStrategy interface:
public interface ISortStrategy
{
IOrderedEnumerable<string> Sort(IEnumerable<string> input);
}
That interface contains only one method that expects a string collection as input and returns an ordered string collection. Now let’s inspect the two implementations:
public class SortAscendingStrategy : ISortStrategy
{
public IOrderedEnumerable<string> Sort(IEnumerable<string> input)
=> input.OrderBy(x => x);
}
public class SortDescendingStrategy : ISortStrategy
{
public IOrderedEnumerable<string> Sort(IEnumerable<string> input)
=> input.OrderByDescending(x => x);
}
Both implementations are super simple, using Language Integrated Query (LINQ) to sort the input and return the result directly.
Tip
When using expression-bodied methods, please ensure you do not make the method harder to read for your colleagues (or future you) by creating very complex one-liners. Writing multiple lines often makes the code easier to read.
The next building block to inspect is the SortableCollection class. It is composed of multiple string items (the Items property) and can sort them using an ISortStrategy. On top of that, it implements the IEnumerable<string> interface through its Items property, making it iterable. Here’s the class:
using System.Collections;
using System.Collections.Immutable;
namespace MySortingMachine;
public sealed class SortableCollection : IEnumerable<string>
{
private ISortStrategy _sortStrategy;
private ImmutableArray<string> _items;
public IEnumerable<string> Items => _items;
public SortableCollection(IEnumerable<string> items)
{
_items = items.ToImmutableArray();
_sortStrategy = new SortAscendingStrategy();
}
public void SetSortStrategy(ISortStrategy strategy)
=> _sortStrategy = strategy;
public void Sort()
{
_items = _sortStrategy
.Sort(Items)
.ToImmutableArray()
;
}
public IEnumerator<string> GetEnumerator()
=> Items.GetEnumerator();
IEnumerator IEnumerable.GetEnumerator()
=> ((IEnumerable)Items).GetEnumerator();
}
The SortableCollection class is the most complex one so far, so let’s take a more in-depth look:
- The _sortStrategy field references the algorithm: an ISortStrategy implementation.
- The _items field references the strings themselves.
- The Items property exposes the strings to the consumers of the class.
- The constructor initializes the Items property using the items parameter and sets the default sorting strategy.
- The SetSortStrategy method allows consumers to change the strategy at runtime.
- The Sort method uses the _sortStrategy field to sort the items.
- The two GetEnumerator methods represent the implementation of the IEnumerable<string> interface and make the class enumerable through the Items property.
With that code, we can see the Strategy pattern in action. The _sortStrategy field represents the current algorithm, respecting an ISortStrategy contract, which is updatable at runtime using the SetSortStrategy method. The Sort method delegates the work to the ISortStrategy implementation (the concrete strategy). Therefore, changing the value of the _sortStrategy field leads to a change of behavior of the Sort method, making this pattern very powerful yet simple. The highlighted code represents this pattern.